L'imagerie cérébrale et l'apprentissage automatique peuvent aider à prédire le risque de maladie mentale
Les chercheurs combinent des données d'imagerie cérébrale et des supercalculateurs pour identifier des modèles dans les données de neuroimagerie qui peuvent aider à prédire le risque de troubles mentaux tels que la dépression ou la démence.
La dépression affecte plus de 15 millions d'adultes américains, soit environ 6,7% de la population américaine, chaque année. C'est la principale cause d'incapacité chez les personnes âgées de 15 à 44 ans.
Le Dr David Schnyer, neuroscientifique cognitif et professeur de psychologie à l'Université du Texas à Austin, a déclaré que la capacité de prédire le risque de maladie mentale n'est pas simple.
Il utilise un supercalculateur pour former un algorithme d'apprentissage automatique capable d'identifier les points communs entre des centaines de patients à l'aide de scanners cérébraux d'imagerie par résonance magnétique (IRM), de données génomiques et d'autres facteurs pertinents, afin de fournir des prévisions précises du risque pour les personnes souffrant de dépression et d'anxiété. .
Les chercheurs étudient depuis longtemps les troubles mentaux en examinant la relation entre la fonction cérébrale et la structure des données de neuroimagerie.
«L’une des difficultés de ce travail est qu’il est essentiellement descriptif. Les réseaux cérébraux peuvent sembler différents entre deux groupes, mais cela ne nous dit pas quels modèles prédisent réellement dans quel groupe vous appartenez », a déclaré Schnyer.
«Nous recherchons des mesures diagnostiques prédictives de résultats tels que la vulnérabilité à la dépression ou à la démence.»
En 2017, Schnyer, en collaboration avec des chercheurs de diverses universités, a effectué une analyse d'une étude de validation de principe utilisant une approche d'apprentissage automatique pour classer les personnes atteintes de trouble dépressif majeur avec une précision d'environ 75%.
Les co-chercheurs comprenaient les Drs. Peter Clasen (École de médecine de l'Université de Washington), Christopher Gonzalez (Université de Californie, San Diego) et Christopher Beevers (Université du Texas, Austin).
L'apprentissage automatique est un sous-domaine de l'informatique qui implique la construction d'algorithmes qui peuvent «apprendre» en construisant un modèle à partir d'échantillons d'entrées de données, puis en effectuant des prédictions indépendantes sur de nouvelles données.
Les chercheurs ont fourni un ensemble d'exemples de formation, chacun marqué comme appartenant à des personnes en bonne santé ou à celles qui ont reçu un diagnostic de dépression. Schnyer et son équipe ont qualifié les caractéristiques de leurs données qui étaient significatives, et ces exemples ont été utilisés pour entraîner le système.
Un ordinateur a ensuite scanné les données, trouvé des connexions subtiles entre des pièces disparates et a construit un modèle qui attribue de nouveaux exemples à une catégorie ou à une autre.
Dans l'étude, Schnyer a analysé les données cérébrales de 52 participants souffrant de dépression et de 45 participants témoins en bonne santé. Pour comparer les groupes, ils ont apparié un sous-ensemble de participants déprimés avec des individus en bonne santé en fonction de l'âge et du sexe, ce qui porte la taille de l'échantillon à 50.
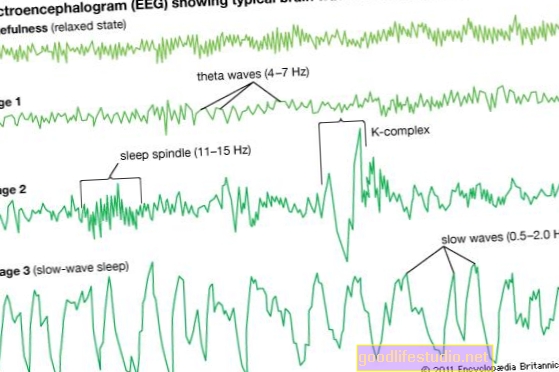
Les participants ont reçu des IRM par imagerie par tenseur de diffusion (DTI), qui marquent les molécules d'eau pour déterminer dans quelle mesure ces molécules sont diffusées au microscope dans le cerveau au fil du temps.
Les chercheurs ont comparé les mesures obtenues entre les deux groupes et ont trouvé des différences statistiquement significatives. Ils ont ensuite réduit les données concernées à un sous-ensemble qui était le plus pertinent pour la classification et ont effectué la classification et la prédiction à l'aide de l'approche d'apprentissage automatique.
«Nous alimentons des données cérébrales entières ou un sous-ensemble et prédisons les classifications des maladies ou toute mesure comportementale potentielle telle que les mesures de biais d'information négative», dit-il.
L'étude a révélé que les données sur le cerveau peuvent classer avec précision les individus déprimés ou vulnérables par rapport aux témoins sains. Il a également montré que les informations prédictives sont distribuées à travers les réseaux cérébraux plutôt que d'être hautement localisées.
«Non seulement nous apprenons que nous pouvons classer les personnes déprimées par rapport aux personnes non déprimées à l'aide des données du DTI, mais nous apprenons également quelque chose sur la représentation de la dépression dans le cerveau», a déclaré Beevers, professeur de psychologie et directeur de l'Institute for Mental Health Recherche à l'Université du Texas, Austin.
«Plutôt que d'essayer de trouver la zone qui est perturbée par la dépression, nous apprenons que les altérations dans un certain nombre de réseaux contribuent à la classification de la dépression.»
L'ampleur et la complexité du problème nécessitent une approche d'apprentissage automatique. Chaque cerveau est représenté par environ 175 000 voxels et il est pratiquement impossible de détecter une relation complexe entre un si grand nombre de composants en regardant les scans.
Pour cette raison, l'équipe utilise l'apprentissage automatique pour automatiser le processus de découverte.
«C'est la vague du futur», dit Schnyer."Nous voyons de plus en plus d'articles et de présentations lors de conférences sur l'application de l'apprentissage automatique pour résoudre des problèmes difficiles en neurosciences."
Les résultats sont prometteurs, mais pas encore suffisamment clairs pour être utilisés comme métrique clinique. Cependant, Schnyer pense qu'en ajoutant plus de données - liées non seulement aux examens IRM, mais aussi à la génomique et à d'autres classificateurs, le système peut faire beaucoup mieux.
«L'un des avantages de l'apprentissage automatique, par rapport aux approches plus traditionnelles, est que l'apprentissage automatique devrait augmenter la probabilité que ce que nous observons dans notre étude s'applique à de nouveaux ensembles de données indépendants. Autrement dit, il devrait se généraliser à de nouvelles données », a déclaré Beevers.
«C'est une question cruciale que nous sommes vraiment ravis de tester dans les études futures.»
Source: Université du Texas à Austin, Texas Advanced Computing Center