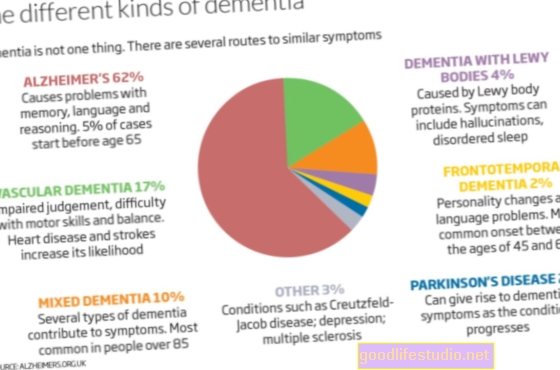
Oups! Pas de «crise de réplicabilité» en science psychologique après tout


Mais l'article révolutionnaire publié en août 2015 par 44 chercheurs, «Estimer la reproductibilité de la science psychologique» (Nosek et al., 2015) semble avoir eu quelques défauts importants. Un nouvel article suggère qu'il n'y a en fait pas de «crise de réplicabilité» en psychologie après tout.
Quatre chercheurs de l'Université Harvard et de l'Université de Virginie (Gilbert et al., 2016) ont publié leurs résultats dans Science (leur site Web de réplications de psychologie héberge toutes les données et le matériel). Ils croient avoir trouvé trois erreurs statistiques majeures dans l'étude originale qui remettent sérieusement en question ses conclusions. Les nouveaux chercheurs affirment: «En effet, les preuves sont cohérentes avec la conclusion opposée - que la reproductibilité de la science psychologique est assez élevée et, en fait, statistiquement impossible à distinguer de 100%.»
Oups.
L'étude originale (Nosek et al., 2015) a tenté de reproduire les résultats de 100 expériences rapportées dans des articles publiés en 2008 dans trois revues de psychologie de haut niveau. La première critique de l'étude est qu'il ne s'agissait pas d'une sélection aléatoire d'études de psychologie. Au lieu de cela, le groupe Nosek a limité sa sélection d'études à seulement trois revues représentant deux dérisoires disciplines de la psychologie, laissant de côté des domaines majeurs comme la psychologie du développement et clinique. Puis Nosek et al. ont utilisé un ensemble complexe de règles et de critères arbitraires qui ont en fait disqualifié plus de 77% des études des trois revues examinées.
La recherche qui commence avec un échantillon biaisé est forcément problématique. En ne partant pas d'un échantillon aléatoire, les chercheurs ont déjà contribué à préparer le terrain pour leurs résultats décevants.


Changeons (considérablement) les études que nous répliquons
Encore pire que de commencer avec un échantillon biaisé et non randomisé, c'est la façon dont les chercheurs ont effectivement procédé aux réplications. Premièrement, les chercheurs ont invité «des équipes particulières à reproduire des études particulières ou ils ont permis aux équipes de sélectionner les études qu’elles souhaitaient reproduire». Plutôt que d’affecter au hasard des chercheurs à des études à répliquer, ils laissent les chercheurs choisir - en apportant les biais de chaque chercheur, pour peut-être choisir les études qui, selon eux, seraient les moins susceptibles d’être répliquées.
Les nouvelles études différaient parfois considérablement des anciennes études qu'elles tentaient de reproduire. Voici juste un exemple (sur au moins une douzaine) de la façon dont l'étude répliquée a introduit des complications importantes:
Dans une autre étude, des étudiants blancs de l'Université de Stanford ont regardé une vidéo de quatre autres étudiants de Stanford discutant des politiques d'admission dans leur université (Crosby, Monin et Richardson, 2008). Trois des intervenants étaient blancs et un était noir. Au cours de la discussion, l'un des étudiants blancs a fait des commentaires offensants sur l'action positive, et les chercheurs ont constaté que les observateurs regardaient beaucoup plus longtemps l'étudiant noir lorsqu'ils pensaient qu'il pouvait entendre les commentaires des autres que lorsqu'il ne le pouvait pas. Bien que les participants à l’étude de réplication soient des étudiants de l’Université d’Amsterdam, ils ont regardé la même vidéo d’étudiants de Stanford parlant (en anglais!) Des politiques d’admission de Stanford.
Les étudiants d'une université d'Amsterdam pourraient-ils vraiment comprendre ce qu'était même l'action positive en Amérique, étant donné les différences culturelles importantes entre la société américaine et celle d'Amsterdam? Étonnamment, les chercheurs qui ont mené la réplication ont déclaré que les études étaient «pratiquement identiques» (et naturellement, ils sont biaisés pour le dire, car il est leur étude). Pourtant, les chercheurs originaux, reconnaissant les différences culturelles significatives dans les deux populations, n'ont pas approuvé la nouvelle étude de réplication.
Gilbert et ses collègues ont trouvé ce genre de problème non pas dans une, mais dans la plupart des études de réplication. Il semble étrange que Nosek et al. estimé que ce type d’incohérences n’aurait pas d’incidence sur la qualité de l’étude (ou la «fidélité», comme les chercheurs l’appellent). Pourtant, il s'agit clairement de différences qualitatives importantes qui auraient sûrement un impact sur la reproductibilité de l'étude.
Nous avons besoin de plus de puissance!


Nosek et ses collègues ont présenté quelques arguments d'homme de paille pour le choix de la conception, que Gilbert et al. abattu un par un dans leur réponse. La conclusion de Gilbert et de ses collègues?
En résumé, aucun des arguments avancés [par les chercheurs en réplication] ne conteste le fait que les auteurs de [la nouvelle étude] ont utilisé une conception de faible puissance, et que (comme nos analyses des données ML2014 le démontrent) cela a probablement conduit à une sous-estimation du taux de réplication réel dans leurs données.
D'autres chercheurs en psychologie ont mené une expérience de réplication similaire en 2014 (Klein et al., 2014). En utilisant une conception puissante, ils ont constaté que la plupart des études de psychologie qu'ils ont examinées se répliquaient - 11 des 13 expériences ont été réexaminées. Pour tester l’impact de la conception à faible puissance de Nosek et al., Gilbert et al. a estimé que le taux de réplication de l’étude de 2014 serait passé de 85% à 34%. Une différence significative et révélatrice.
Alors, que savons-nous vraiment de la reproductibilité de la science psychologique?
Plus que ce que nous pensions. Compte tenu de la critique de Gilbert et al. Et de la réponse mawkish des chercheurs originaux, il semble plus probable que Nosek et al. l'étude était gravement défectueuse.
Il semble que la science psychologique soit plus reproductible que nous ne le pensions - une bonne nouvelle pour la science et la psychologie.
Références
Gilbert, D., King, G., Pettigrew, S. et Wilson, T. (2016). Commentaire sur «Estimer la reproductibilité de la science psychologique». Science, 351, 1037a-1037b.
Gilbert et coll. (2016). Une réponse à la réponse de notre commentaire technique sur «Estimer la reproductibilité de la science psychologique».
Klein, RA, Ratliff, M Vianello, RB Adams Jr, Š Bahník, MJ Bernstein, et al. (2014). Etude de la variation de la réplicabilité: un projet de réplication «de nombreux laboratoires». Psychologie sociale, 45 ans, 142-152
Nosek et coll. & Open Science Collaboration. (2015). Estimation de la reproductibilité de la science psychologique. Science, 349. DOI: 10.1126 / science.aac4716
Nosek et coll. (2016). Réponse au commentaire sur «Estimation de la reproductibilité de la science psychologique». Science, 351, 1037. DOI: 10.1126 / science.aad9163